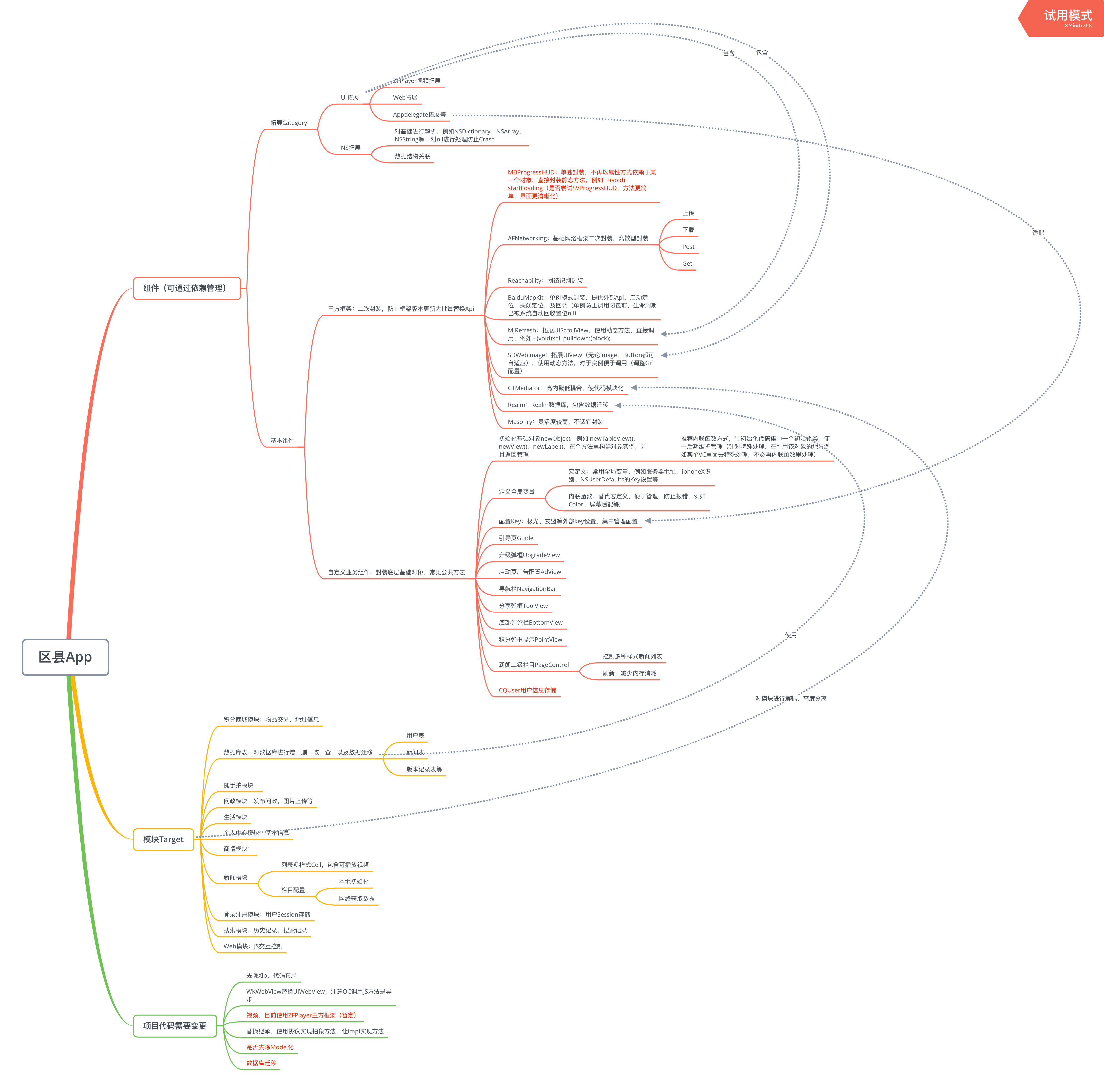
1 组件化模块化
网上有许多讲解组件化、模块化开发的文章,但是通常情况下,容易把这两种概念混为一谈,并没有加以区分,而且许多人对于组件、模块的定义也不甚明了,下面,我将会为大家讲解组件化、模块化的区别,以及在我们相关的工作项目中的分层。
1.1 组件化模块化的广泛定义
| 组件 | 目的 | 特点 | 接口 | 成果 | 架构定位 |
|---|---|---|---|---|---|
| 组件 | 重用、解耦 | 高重用、低耦合 | 无统一接口 | 基础库、基础组件 | 纵向分层 |
| 模块 | 隔离、分装 | 高内聚、低耦合 | 统一接口 | 业务框架、业务模块 | 横向分块 |
- 组件:最初的目的是代码重用,功能相对单一或独立。在整个系统的代码层次上位于最底层,被其他代码所以来,所以说组件是纵向分层。
- 模块:最初的目的是将统一类型的代码整合在一起,所以模块的功能相对复杂,但都属于同一个业务。不同的模块之间,也会存在依赖关系,但是大部分都是业务之间的相互跳转,从地位上而言,都是属于同一层次的平级关系。
1.2 谈谈自己对于组件化模块化的理解
从上面的结构图标以及组件定义,我们能够清楚的知道,组件更偏向于代码的底层,而且是公用的底层,所以是高重用,纵向分层;组件又是属于低耦合,组件之间,很少存在相互引用的问题,属于基础库,没有统一的接口,就是说,组件本身也是要执行单一原则,一个组件只做一件事情,而开发者在高层编码的时候,可以使用组件组装成一完整的功能块。
来看一下模块,模块层,更偏向于业务层,主要更大的业务功能块,而业务层又是用户能够直接参与的操作,所以业务层相对更复杂。模块层是一个功能复杂的代码块集合,它可以包含不同的组件,实现高内聚,内部之间相互嵌套使用,而后开放一个公共API接口供外部使用,实现了低耦合的效果,这样的就达到了模块层完全独立,而所有的模块层都是可以相互调用的,不存在A模块是基于B模块完成,所以模块层又是属于横向分块。
我们实际的项目中,具有如此的问题—-高耦合、低内聚、无重用。在实际项目移植的时候,迁移A模块,关联了许多公共模块B,我们还需要把这些B模块一路带过去,特别是项目积累越来越多,这样的问题越来越明显,这时候我们也许需要一定的代码重构。
- 那么代码重构是什么?
将重复的代码合并为一份,也就是重用,我们可以看到组件化开发的定义,它的着重点就是重用,我们重构的效果就是要提炼出一个个组件给不同的功能使用。组件虽然位于代码的底层,但是偶尔会有依赖关系,而我们所做的就是尽量去减少组件的相互依赖,达到独立的效果,记住组件的原则就是高重用、低依赖。模块是基于大型业务,按关注点进行划分,只需要开放公用API让开发者直接使用即可。对了,还有一个问题,就是模块间的解耦,我们的项目需求,难免会有一些奇葩的,你懂得,然而我们面对问题,不能逃避,要去面对,就有了模块之间相互引用,模块之间相互引用,少不了导入头文件,关联文件,而我们的解决方案就是动态化解决,使用路由方式,来分发不同的模块事件,而且避免了模块间的相互引用。e'g,微信的朋友圈和微信的好友聊天功能,是两个不同的模块层,我们可以,如果腾讯以后再开发个类似微信的App,那么它可以把朋友圈或者聊天功能这个模块直接移植到另一个App上直接使用,减少了人力成本,这展示出了模块化的可移植性且独立,而在微信,我们可以在好友聊天里,点击好友的头像,跳转到好友的朋友圈列表,可以查看好友的朋友圈信息;相反,我也可以在朋友圈列表点击头像跳转到好友聊天界面,这样,就实现了模块之间的相互引用,而且引用十分简单,只需要调用公共开放的API传入一些用户id之类的信息,完全的独立,横向分块。那么,现在我们再来说,微信的朋友圈列表需要展示图片信息,好友聊天功能发送表情包也需要展示图片信息,他们的这两个功能重复了,那么,这时候,肯定有一个公共的组件,就是 Image 组件,无论是朋友圈模块还是好友聊天模块都会引用该组件,所以说,组件是高重用,而且是在代码的底层,属于纵向分层。2 对iOS端项目进行模块分区
在这一节,针对于iOS端的项目,我们会进行明确的区分责任,主要有以下几点:
- 组件化–实现基础库
- 中间件–实现各模块或组件之间的串联
- 模块化–实现各个业务层之间的封装
看如下的图片:
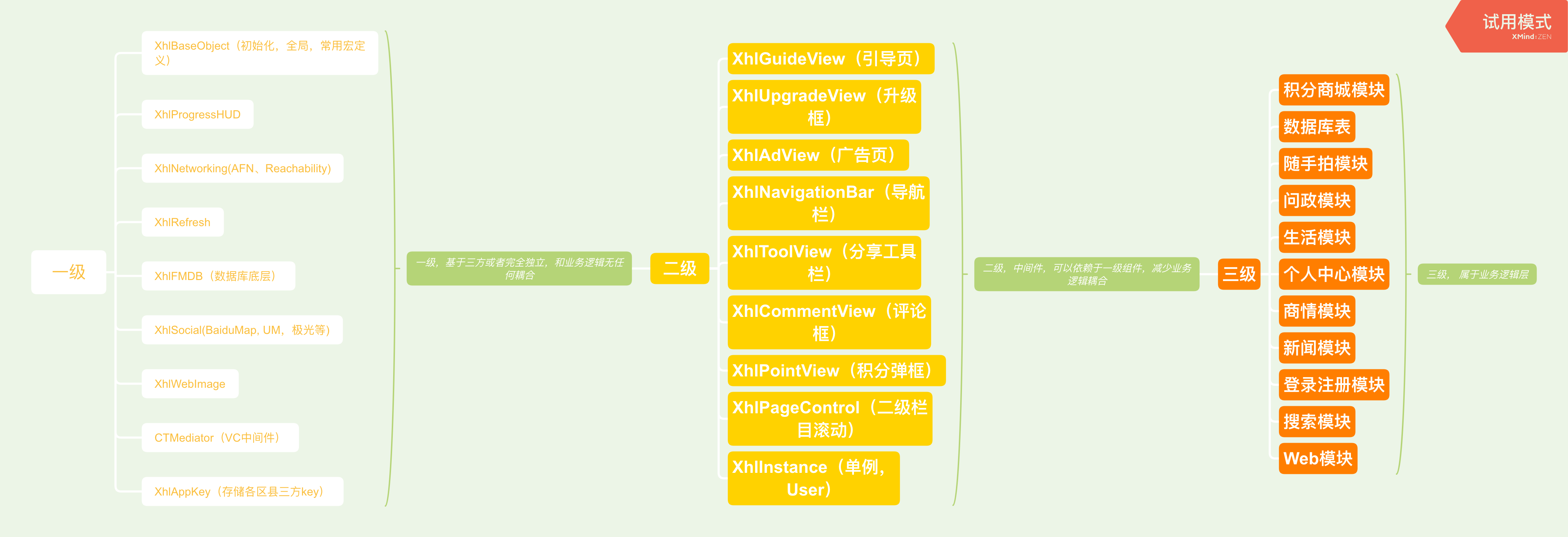
2.1 组件化
2.1.1 网络层组件
iOS网络层的框架,一般使用NSURLConnection和NSURLSession,但是我们看见在苹果的官方文档有如下的信息所示:
DEPRECATED: The NSURLConnection class should no longer be used. NSURLSession is the replacement for NSURLConnection@discussion The interface for NSURLConnection is very sparse, providing
only the controls to start and cancel asynchronous loads of a
URL request.
我们在这里可以看见,苹果官方文档已经在 9.0 系统就放弃了 NSURLConnection,从而使用 NSURLSession 来代替 NSURLConnection。
NSURLSession的使用十分的简单,首先根据会话创建一个请求 NSURLSessionTask,然后执行这个Task任务,而 NSURLSessionTask 本身是一个抽象类,主要是根据不同的需求,来使用它的子类,其子类常用的包含这几个:
NSURLSessionDataTask
NSURLSessionDownloadTask
NSURLSessionUploadTask
我们使用NSURLSession发送GET请求的方法和NSURLConnection的方法类似,过程步骤如下:
确定请求路径
创建请求对象
创建会话对象 NSURLSession
根据会话对象创建请求任务 NSURLSessionDataTask
执行NSURLSessionTask
得到返回数据,解析数据
我们可以查看如下的GET代码示例:
1 | NSURL *url = [NSURL URLWithString:@"http://127.0.0.1:3000/login?username=dd&pwd=ww"]; |
在下面的代码我们将看见POST代码示例:
1 | NSURLSession *session = [NSURLSession sharedSession]; |
以上,我们使用的是系统自带的框架简单封装的网络框架,而在我们的实际项目中,我们使用一个三方库框架,大多数的iOS项目都使用该框架,AFNetWorking。而该框架主要分为四个模块:
- 处理请求和回复的序列化模块:Serialization
- 网络安全模块:Security
- 网络监测模块:Reachability
- 处理通讯的会话模块:NSURLSession
其中NSURLSession是我们开发者常用的模块,毕竟所有的请求和数据流通都是从这个模块反应出来的,其余的几个模块相对来说比较独立
2.1.1.1 Serialization序列化模块
序列化模块主要包括请求序列化 AFURLRequestSerialization 和响应序列化 AFURLResponseSerialization,它的主要功能可以这样来理解。
- AFURLRequestSerialization用来将字典参数编码成URL传输参数,并提供上传文件的基本功能实现。
- AFURLResponseSerialization用来处理服务器返回数据,提供返回码校验和数据校验的功能。
2.1.1.2 Security模块
AFURLResponseSerialization用来处理服务器返回数据,提供返回码校验和数据校验的功能。我们目前项目的做法,是把SSL证书放入放入项目内,在进行网络请求的时候使用APP内的证书进行验证,我们来看一下 AFN 的关于安全的逻辑是如何实现。
AFSecurityPolicy
**AFSecurityPolicy使用固定的x.509证书和安全链接上的公钥来评估服务器的受信任程度。
在你的应用中添加绑定的SSL证书有利于防止“中间人攻击”和其他缺陷。
应用在处理敏感的客户数据或者金融信息时,强烈建议在HTTPS的基础上使用SSL绑定的配置和授权来进行网络通讯。**
这是一个安全策略对象,而以上的解释是AFN管理人员对于该对象的定义,我们来看以下的属性:
1 | /** |
校验证书都是通过调用系统库<Security/Security.h>的方法。AFNetworking所做的操作主要是根据设置的AFSecurityPolicy对象的属性进行证书验证。当SSLPinningMode不进行设置或设置为AFSSLPinningModeNone时,将不进行验证,设置为AFSSLPinningModeCertificate会使用证书进行验证,设置为AFSSLPinningModePublicKey将直接使用证书里面的公钥进行验证。可以通过设置pinnedCertificates属性来设置验证所用的证书,也可以通过+certificatesInBundle:方法加载单独放在一个Bundle里的证书,如果不设置,AFNetworking会使用NSBundle的+bundleForClass:方法将放在AFNetworking.framework里面的cer文件作为验证所用证书。
2.1.1.3 Reachability网络监测模块
这里我们就不在进行详细的解释,直接贴上官方文档:
AFNetworkReachabilityManager用于监听域名或者IP地址的可达性,包括WWAN和WiFi网络接口。
Reachability可以被用来确定一个网络操作失败的后台信息,或者当连接建立时触发网络操作重试。
它不应该用于阻止用户发起网络请求,因为可能需要第一个请求来建立可达性。
2.1.1.4 NSURLSession模块
我们来看一下 AFURLSessionManager 这个属性的对象的内容:
1 | //属性 |
AFURLSessionManager将每一个task都分别交给一个AFURLSessionManagerTaskDelegate对象进行管理,AFURLSessionManagerTaskDelegate相当于扩展了NSURLSessionTask的属性。
1 | @interface AFURLSessionManagerTaskDelegate : NSObject <NSURLSessionTaskDelegate, NSURLSessionDataDelegate, NSURLSessionDownloadDelegate> |
AFURLSessionManagerTaskDelegate通过实现NSURLSessionTaskDelegate、NSURLSessionDataDelegate和NSURLSessionDownloadDelegate协议的相关方法来监听网络请求的完整过程,并操作它的属性值mutableData、uploadProgress等,并在对应时刻回调block。
AFNetworking通过AFURLSessionManager来对NSURLSession进行封装管理。AFURLSessionManager简化了用户网络请求的操作,使得用户只需以block的方式来更简便地进行网络请求操作,而无需实现类似NSURLSessionDelegate、NSURLSessionTaskDelegate等协议。用户只需使用到NSURLSessionTask的-resume、-cancel和-suspned等操作,以及在block中定义你需要的操作就可以。
为了在任务的暂停和恢复时发送通知,AFNetworking使用了动态swizzling修改了系统的-resume和-suspend方法的IMP,当调用-resume时发送通知,关键代码如下:
1 | /* 遍历NSURLSessionDataTask类及其父类的resume和suspend方法 */ |
我们可以总结出AFNetworking的工作流程:
建一个task和一个delegate来管理task,并将它们保存到字典里
实现NSURLSessionDelegate等协议的方法,监听任务状态,通过block回调
当任务完成时,移除task和delegate
而我们在基于AFN使用的时候,也会把AFN进行二次封装,封装的步骤如下:
将AFN封装成单例,全局使用
使用集约型方式封装基本方法,防止直接使用AFN时,发生版本更新而导致API的变更,这样可以集中管理AFN的代码。
使用离散型封装,基于集约型方式,对于每一个API接口,单独封装一个请求方法,保证单一原则
统一成功回调函数和失败回调函数,保证数据的一致性
利用https加密保证数据安全,同时对于底层关键代码进行混淆,防止逆向
2.1.2 Realm数据库
在iOS端,我们经常使用的数据库,CoreData 和 Sqlite,众所周知, Sqlite 需要我们使用的SQL语句,而且占用资源很低,处理速度也十分快,而Coredata使用映射关系来存储数据,虽然其也是基于Sqlite封装,但是对于Coredata的API很多开发者都无法接受,用起来十分复杂。
我们的项目,也是使用基于 SQLite 封装的一个三方库,叫做 FMDB,FMDB是针对libsqlite3框架进行封装的三方,它以OC的方式封装了SQLite的C语言的API,使用步骤与SQLite相似,
可以来看一下它的优点:
使用时面向对象,避免了复杂的C语言代码
对比苹果自带的Core Data框架,更加轻量级和灵活
提供多线程安全处理数据库操作方法,保证多线程安全跟数据准确性
当然,既然我们的主题是 Realm 数据库,那我们定要说 FMDB 的缺点:
需要开发者手动写入SQL语句,增删改查,任务繁重
数据迁移问题,需要自己配置,或者再次加入三方库来才能正常使用
需要自己转换自定义模型
非跨平台
这几点问题,就是我们在项目中遇到的实际问题,最近研究看见了 Realm 数据库,很不错,我来简单的介绍一下该数据库:
Realm是由Y Combinator公司孵化出来的一款可以用于iOS(同样适用于Swift&Objective-C)和Android的跨平台移动数据库。历经几年才打造出来,为了彻底解决性能问题,核心数据引擎用C++打造,并不是建立在SQLite之上的ORM,所以Realm相比SQLite和CoreData而言更快、更好、更容易去使用和完成数据库的操作花费更少的代码。它旨在取代CoredData和sqlite,它不是对coreData的简单封装、相反的,Realm它使用了它自己的一套持久化存储引擎。而且Realm是完全免费的,这不仅让它变得更加的流行也使开发者使用起来没有任何限制。Realm是一个类MVCC数据库,每个连接的线程在特定的时刻都有一个数据库的快照。MVCC(Multi-Version Concurrent Control 多版本并发控制)在设计上采用了和Git一样的源文件管理算法,也就是说你的每个连接线程就好比在一个分支(也就是数据库的快照)上工作,但是你并没有得到一个完整的数据库拷贝。Realm和一些真正的MVCC数据库如MySQL是不同的,Real在某个时刻只能有一个写操作,且总是操作最新的数据版本,不能在老版本操作。
通常的数据库操作是这样的,数据存储在磁盘的数据库文件中,我们的查询请求会转换为一系列的SQL语句,创建一个数据库连接。数据库服务器收到请求,通过解析器对SQL语句进行词法和语法语义分析,然后通过查询优化器对SQL语句进行优化,优化完成执行对应的查询,读取磁盘的数据库文件(有索引则先读索引),返回对应的数据内容并存储到内存中,数据还需要序列化成内存可存储的格式,最后数据还要转换成语言层面的类型,比如Objective-C的对象等。
而Realm完全不同,它的数据库文件是通过memory-mapped,也就是说数据库文件本身是映射到内存中的,Realm访问文件偏移就好比文件已经在内存中一样(这里的内存是指虚拟内存),它允许文件在没有做反序列化的情况下直接从内存读取,提高了读取效率。
为了增加大家对于 Realm 数据库的印象,我列出以下的数据,大家可以对比:
| 数据条数 | 1000000 | 1000000 | 10000 | 10000 |
|---|---|---|---|---|
| 数据库 | Realm | FMDB | Realm | FMDB |
| 存储时间/秒 | 17 | 34 | 0.1 | 0.3 |
| 读取时间/秒 | 0.01 | 20 | 0.01 | 0.1 |
| 大小 | 201M | 39M | 9M | 352K |
这里允许我来一个表情包

从量级而言,确实 Realm 更优秀,但是唯一的缺点也是暴露无遗,就是数据库存储的大小,很让人难受。
忽略缺点,我们要正视它的优点:
易安装:正如你在将要看到的使用Realm工作。安装Realm就像你想象中一样简单。在Cocoapods中使用简单命令,你就可以使用Realm工作。而AppStore也提供了该工具专门查看RL数据库
速度上:Realm是令人无法想象的快速使用数据库工作的库。Realm比SQLite和CoreData更快,这里的数据就是最好的证明。
跨平台:Realm数据库文件能够跨平台和可以同时在iOS和Andriod使用。无论你是使用Java, Objective-C, or Swift,你都可以使用你的高级模型。
可扩展性:在开发你的移动App特别是如果你的应用程序涉及到大量的用户和大量的记录时,具有良好的可扩展性是非常重要的。
易读性:Realm团队提供了可读的,非常有组织的并且丰富的文档。如果你遇到什么问题通过Twitter、GitHub或者Stackoverflow与他们交流。
可靠性:Realm已经被巨头公司使用在他们的移动App中,像Pinterest, Dubsmash, and Hipmunk。
免费性:使用Realm的所有功能都是免费的。
懒加载:只有当你真正访问对象的值时候才真正从磁盘中加载进来。
迁移:完美支持数据迁移。
而且,Realm数据库,在使用的时候,只需要继承它默认的对象即可,我们可以直接操控自定义对象来完成对数据库的增删改查,不再像FMDB需要操控SQL数据来完成,利于维护,当然,Realm数据库也支持SQL语句。
Realm 数据库不仅可以做到把键值对存储进数据库,也提供的专门的方法,让我们把某些不想存入数据库的临时属性放置在数据库外,这个方法我们只需要把所有的 key 以数组形式列出来即可:
1 | + (nullable NSArray *)ignoredProperties; |
1 | 还有非空字段的设置: |
1 | 给属性设置默认值: |
1 | 在二维表中,主键是个至关重要的属性,他表示了那个字段是可以唯一标记一行记录的,不可重复。Realm也是支持这一的特性: |
1 | @implementation RLMObject (XHLDatabase) |
1 | 数据迁移的实现,这里也可以用代码来展示 |
这里我们可以看一下Realm数据库
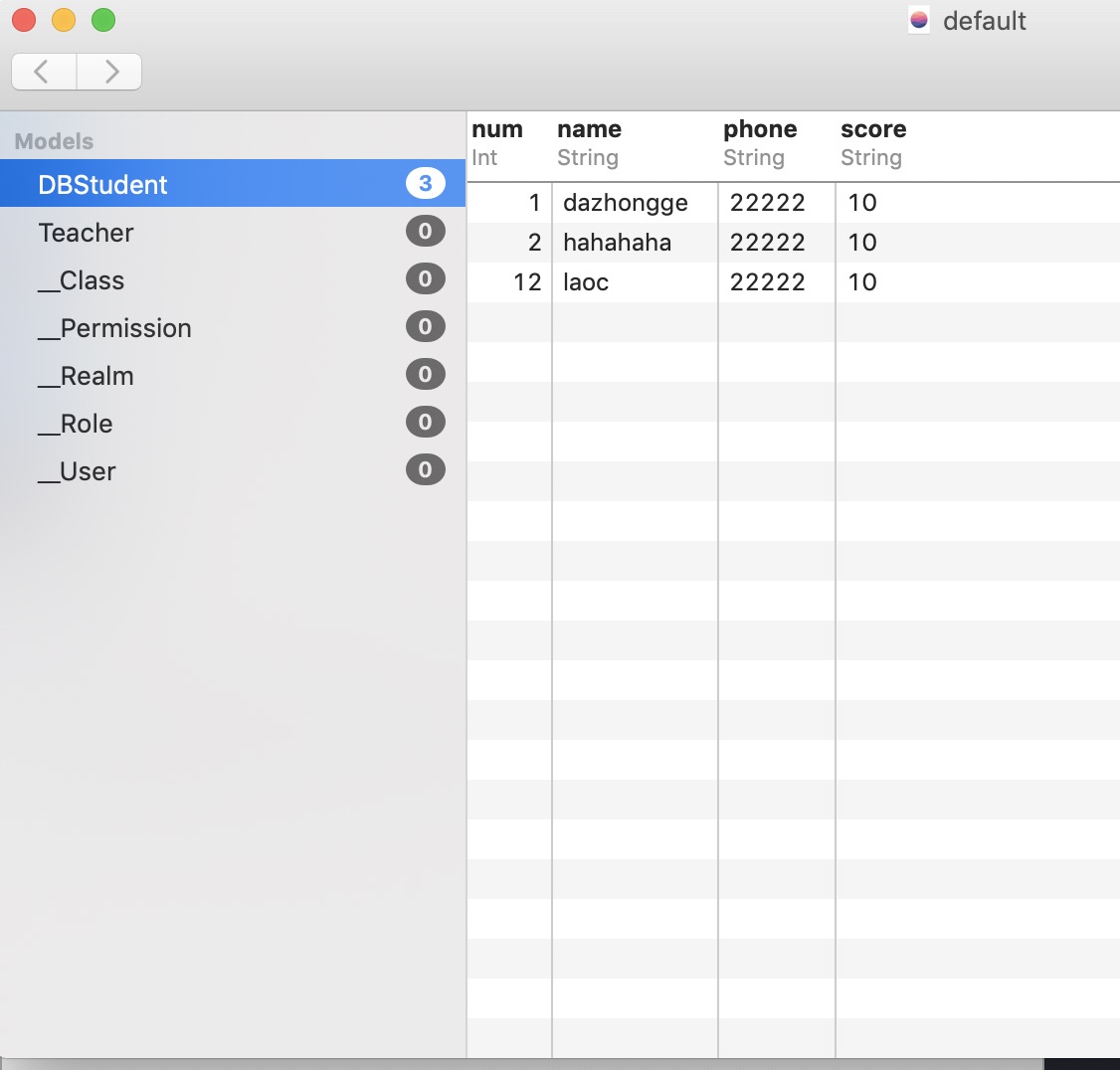
在我们的项目中,主要有两点,Realm能够很好的解决我们的问题
- 对数据库的增删改查不用关心SQL语句,直接操作对象即可
- 支持数据库迁移
当然,Realm也有几点注意事项:
- 跨线程访问数据库,realm一定要新建一个,当前线程重新获取最新的Realm
- 自己封装一个realm全局单例实例意义不大,虽然在以往的FMDB数据库,我们会封装单例来管理,但是同一个Realm对象是不支持跨线程操作realm数据库的。其实RLMRealm *realm = [RLMRealm defaultRealm]; 这句话就是获取了当前realm对象的一个实例,其实实现就是拿到单例。所以我们每次在子线程里面不要再去读取我们自己封装持有的realm实例了,直接调用系统的这个方法即可,能保证访问不出错。
- 建议每个model 都设置主键,方便add和update
2.2 中间件
中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯。是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递。通过中间件,应用程序可以工作于多平台或OS环境。
在我们进行组件化模块化分区的时候,就产生了一个问题,我们如何关联这些 块,对于组件而言,我们可以直接使用,但是模块呢?模块如果直接的引用,必定造成不小的后果
后期维护成本高,因为高耦合,模块移植难度大!!!
这时候需要我们使用中间件来串联我们的各个模块与主程序。
2.2.1 Runtime
runtime是一门动态语言基于C和汇编,iOS系统自带公用的动态库,程序都是有运行时系统动态创建所需要的对象,而其核心机制是消息传递。
OC是运行时语言,在应用程序运行时来决定函数内部实现什么具体的方法,在运行期间,可以创建、检查、修改类。
我们来说一下消息传递机制吧,系统首先查找消息接受对象,通过对象isa指针查找其类对象,在类对象中查找方法列表method_lists,如果没有,则去父类查找,找到对应方法执行IMP指针,否则抛出异常导致crash。
关于消息转发机制,可以这样来描述,当调用一个方法,首先发送消息在类对象中搜索方法列表,如果未找到会一直沿着继承树向上搜索,如果找不到,回执不识别方法,crash。此流程分为动态方法解析、备用接受者、完整消息转发。
关于 Runtime 在iOS中的运用,算不上多,但是往往能够起十分关键的作用
- 关联对象,AOP面向切面编程
- 自动归档与解档
- KVO实现原理
- 热修复技术
接下来我会根据这四点进行描述。
2.2.1.1 关联对象
虽然Objective-C是基于C语言开发,但却是OOP,说到OOP,总会想起熟悉的那三大特性:
- 封装
- 继承
- 多态
然后,在实际的开发中,我们往往被固定的思维模式所 禁锢,从而导致在开发中,解决问题不会那么变通。当然,我不是针对OOP的设计人,只是说,在我们开发过程中,程序设计的一些思想,对我们好处有很多,当然也有不适合我们的地方,最终要看我们自己的抉择,去选择一个合适自己的方案。
继承从代码复用的角度来说,特别好用,也特别容易被滥用和被错用。不恰当地使用继承导致的最大的一个缺陷特征就是高耦合。
举个例子,我们区县所使用的新闻搜索框,本来是一个完整的功能,但是后来,产品提了一个需求,新增一个问政搜索框,那好,我们根据面向对象的思想,去继承新闻搜索框,Over,任务完成。几天后产品又来了个需求,把新闻搜索框的UI进行大调整?怎么办?改了新闻搜索框我的问政搜索框也会跟着改呀?复制一份代码出来?真的复杂,脑壳大,在想不想用继承了,高耦合。日复一日年复一年,这样的累积越来越多,让我们失去了兴趣,可见,代码复用也是分类别的,如果当初只是出于代码复用的目的而不区分类别和场景,就采用继承是不恰当的。我们应当考虑以上3点要素看是否符合,才能决定是否使用继承。
这时候,我们为什么不使用AOP呢,AOP面向切面编程,把我们多次重用或者不同的代码,单独提取出来,封装成单独的对象,这样,即使在进行项目移植的时候,低耦合,只需要我需要的,不用再拖拽相关的其他文件。
A类,B类,C类,都属于平级类对象,我们需要给这3个类都添加一个 d 属性,我们直接使用关联对象,使 A->d,B->d,C->d,这样绑定起来,而且 A、B、C 三个类没有没有任何的关联,又得到了 d 属性,是不是很完美的解决方案。而iOS本身是支持分类拓展的,虽然拓展不能支持给对象添加属性,但是我们可以利用Runtime机制动态给对象添加属性,可以把一个对象拆分成多个对象来单独管理,便于维护,降低耦合,完全可以达到使用组合分类来实现继承想要的效果,可以较好的解决我们的需求问题。
2.2.1.2 归档解档
iOS少不了自定义模型,而如果要把自定义的模型进行持久存储,又必须要遵守 NSCoding 协议,这个协议是什么呢,我们可以来看一下代码
1 | @interface Student : NSObject<NSCoding> |
上面的两个方法,分别是归档和解档,如果当我们一个自定义模型有几十个属性呢?难道还需要我们一个一个的手动写入?那未免也太复杂了吧,这时候就可以利用Runtime机制来实现自动的归档解档:
1 | - (void)encodeWithCoder:(NSCoder *)encoder |
其实 Ivar 是代表变量,利用Runtime遍历所有的变量,获取模型的变量名,然后自动生成键值对。即使有100个属性都不会在担心了。
2.2.1.3 KVO实现原理
这话题总让人想起面试的情节,
面试官会习惯性的问你————“你说一下KVO和KVC的区别”。
面试者也是习惯性的回答————“KVC是键值对,而KVO是使用观察者模式来监听某属性的变化。。。。。。”
面试官————“没了???”
面试者————“没了…(脸上笑嘻嘻,心里xxx)”
其实KVO可以这样理解:
Apple使用了 isa-swizzling来实现 KVO。当观察对象A时,KVO机制动态创建一个新的名为:NSKVONotifying_A的新类,该类继承自对象A的本类,且 KVO为 NSKVONotifying_A重写观察属性的 setter方法,setter方法会负责在调用原 setter方法之前和之后,通知所有观察对象属性值的更改情况。在这个过程,被观察对象的 isa指针从指向原来的 A类,被KVO机制修改为指向系统新创建的子类NSKVONotifying_A类,来实现当前类属性值改变的监听;
所以当我们从应用层面上看来,完全没有意识到有新的类出现,这是系统“隐瞒”了对 KVO的底层实现过程,让我们误以为还是原来的类。但是此时如果我们创建一个新的名为“NSKVONotifying_A”的类,就会发现系统运行到注册 KVO的那段代码时程序就崩溃,因为系统在注册监听的时候动态创建了名为 NSKVONotifying_A的中间类,并指向这个中间类了。
KVO的键值观察通知依赖于 NSObject 的两个方法:willChangeValueForKey:和 didChangeValueForKey:,在存取数值的前后分别调用 2 个方法:
被观察属性发生改变之前,willChangeValueForKey:被调用,通知系统该 keyPath的属性值即将变更;
当改变发生后, didChangeValueForKey:被调用,通知系统该keyPath的属性值已经变更;之后, observeValueForKey:ofObject:change:context:也会被调用。且重写观察属性的setter方法这种继承方式的注入是在运行时而不是编译时实现的。
2.2.1.4 热修复
热修复技术确实给Native开发节约了很大的时间成本,而做到通过JS调用和改写OC方法最根本的原因是 Objective-C 是动态语言,OC上所有方法的调用/类的生成都通过 Objective-C Runtime 在运行时进行,我们可以通过类名/方法名反射得到相应的类和方法。
2.2.2 Route
其实,最初了解Route的时候,是在以前学习NodeJS开发了解到的,当时在项目中了解到这样一个代码块:
1 | var _ = require('underscore'); |
根据不同的链接地址,由中间路由分发到不同的页面,这样让所有的跳转逻辑统一处理,直观,而且低耦合,不会让文件之间相互引用。我们平常的iOS开发中,页面间的跳转,举个例子吧:
页面A跳转页面B,需要在页面A中导入B页面,在A页面写入逻辑操作传参等等,而C页面跳转B页面,也需要同A页面一样的操作,如果有100个页面都需要跳转B页面呢?那岂不是要依赖100次?这时候,我们把所有的页面跳转请求集中在一个路由管理,根据不同的请求URL再由路由决定跳转不同的页面。由于有多个不同的业务模块,保证每一个业务模块有且仅有一个路由,在调用的时候,直接通过路由分发跳转不同页面、传参等操作。
当然,这里也涉及到了Runtime机制,我们所有的项目都会依赖一个公共文件,这个公共文件我们暂时叫做 A 吧,A里面有一个核心的方法:
1 | - (id)performTarget:(NSString *)targetName action:(NSString *)actionName params:(NSDictionary *)params shouldCacheTarget:(BOOL)shouldCacheTarget |
以上我做了代码的截取,我们只看关键的地方
1 | NSString *targetClassString = [NSString stringWithFormat:@"Target_%@", targetName]; |
这样,就能够使我们的模块与模块之间能够相互引用,串联所有的代码,达到我们想要的效果:
- 解耦:减少文件的依赖,让模块移植更加方便
- 处理事务:集中管理逻辑,清晰简洁
- 参数:参数集中放置于路由,结合逻辑处理
- 模块之间调用:通过Runtime动态机制,实现模块层之间相互调用且低耦合
2.3 模块化
模块化就如我们先前所说,主要偏向于业务层,功能繁杂,且是横向分块。
2.3.1 WKWebView
我们以前所有的项目都是用 UIWebView,UIWebView的能力很丰富,可以将其理解为一个内置的webkit,具有页面解析、排版布局、执行javascript脚本等功能。WebKit是由Apple公司开发的开源浏览器内核,应用于Apple Safari浏览器。此外,UIWebView还支持浏览word/excel/ppt/pdf/page/number等多种文档格式。
但是,UIWebView很多功能不齐全,更像是一个阉割版的WebKit。
WebKit主要有三大模块:
- WebCore:是最核心的部分,负责HTML、CSS的解析和页面布局渲染
- JavaScriptCore:负责JavaScript脚本的解析执行,通过bindings技术和WebCore进行交互
- Port:结合上层应用,封装WebCore的行为为上层应用提供API来使用
而WKWebView就是苹果目前推荐的控件,它具有以下的优势:
- 多进程,在app的主进程之外执行
- 使用更快的Nitro JavaScript引擎
- 消除某些触摸延迟
- 支持服务端的身份校验
- 支持对错误的自签名安全证书和证书进行身份验证
- 异步执行处理JavaScript
2.3.1.1 多进程
WKWebView为多进程组件,也意味着会从App内存中分离内存到单独的进程(Network Process and Rendring Process)中。当内存超过了系统分配给WKWebView的内存时候,会导致WKWebView浏览器崩溃白屏,但是App不会Crash。(app会收到系统通知,并且尝试去重新加载页面)。
相反的,UIWebView是和app同一个进程,UIWebView加载页面占用的内存被计算为app内存占用的一部分,当app超过了系统分配的内存,则会被操作系统crash。在整个过程中,会经常收到iOS系统的通知用来防止app被系统kill,但是在某些时候,这些通知不够及时,或者根本没有返回通知。
2.3.1.2 Nitro JavaScript引擎
WKWebView使用和手机Safari浏览器一样的Nitro JavaScript引擎,相比于UIWebView的JavaScript引擎有了非常重要的性能提升
2.3.1.3 消除触摸延迟
UIWebView和WKWebView浏览器组件会将触摸事件解释后发送给app,因此,我们无法提高触摸事件的灵敏度或速度。在UIWebView上的任何触摸事件会被延迟300ms,用以判断用户是单击还是双击。这个机制也是那些基于HTML的web app一直不被用户接受的重要原因。
在WKWebView中,测试显示,只有在点击很快(<~125ms)的时候才会添加300ms的延迟,iOS将其解释为更可能是双击“点击缩放”手势的一部分,而不是慢点击(>〜125 ms)后。更多细节在这里,为了消除所有触摸事件(包括快速点击)的触摸延迟,您可以添加FastClick或另一个消除此延迟的库到您的内容中。
2.3.1.4 支持服务端的身份校验
与不支持服务器认证校验的UIWebView不同,WKWebView支持服务端校验。实际上,这意味着在使用WKWebView时,可以输入密码保护网站。
2.3.1.5 支持对错误的自签名安全证书和证书进行身份验证
通过“继续”/“取消”弹出窗口,WKWebView允许您绕过安全证书中的错误(例如,使用自签名证书或过期证书时)。
2.3.1.6 异步执行处理JavaScript
UIWebView处理JS交互是同步的,而WKWebView是异步处理,这是两者不同的地方。
既然这里说道了JS,那我就说一下h5与native的交互。
js交互主要分为两种情况
app调用h5
h5调用app
前者理解起来很简单,因为app是宿主,可以直接访问h5,此时此刻,可以理解为h5和native在同一个内存空间,可以直接调用h5的方法,就像调native自己的方法一样。
而h5调用native,就相对要比前者绕一些。由app向h5注入一个全局js对象,然后在h5直接访问这个对象,然后由h5发起一个自定义协议请求,app拦截这个请求后,再由app调用 h5 中的回调函数,怎么说,最后一步回调也可以理解成 app调用h5,不同的地方就是 app 需要向h5注入对象,然后由h5发起协议请求。
在iOS中,有2种比较好的方式来处理js交互:
- WebViewJavaScriptBridge:一个开源三方库,使用率很高
- WKMessageHandler:Apple官方推荐使用的交互方式
使用如下:
1 | [self.bridge registerHandler:@"ObjC Echo" handler:^(id data, WVJBResponseCallback responseCallback) { |
再来让我们看一下 WKMessageHandler:
1 | 这里是OC注入一个JS方法 |
相比而言,三方库确实要好很多,一个方法,直接了当,而后者苹果推出的方法则是把这个步骤分为了2步来完成。
其实,以上两种方式都很好,比如说:
- 在JS中写起来简单,不用再用创建URL的方式那么麻烦了
- JS传递参数更方便。使用拦截URL的方式传递参数,只能把参数拼接在后面,如果遇到要传递的参数中有特殊字符,如&、=、?等,必须得转换,否则参数解析肯定会出错。而如上的方式,在app端可以获取到需要的键值对NSDictionary或NSArray数组。
#3 私有库
在iOS开发中,cocoapods是常用的三方库管理工具,我们日常开发不想造轮子,就是用开源库,是属于公共库,而如果是我们不想公布的代码,那么就可以选用私有库来存放代码,一般而言,cocoapods结合git更好管理,但是由于公司是使用的svn,所以花了很多时间去研究如何在svn上搭建私有仓库。
在svn上搭建私有库大致步骤和在git上搭建代码库是一样的,我来说一下细小的区别吧:
- 使用镜像源:保证镜像源是 https://gems.ruby-china.com,否则需要替换上述地址
- 安装svn插件:安装cocoapods-repo-svn插件,并且在终端登录svn账号,否则无法使用
- 更新索引文件:更新search_index.json文件,保证私有仓库索引信息得到更新
- 依赖安装:在podfile文件,指定私有仓库路径并且安装私有库的版本。
#4 总结
组件化模块化的开发,主要是为了高耦合、项目移植等问题,当然,也会节省大家的开发时间,更利于管理代码。